









Docker环境下使用CentOS7.8配置Hadoop3.3.0完全分布式集群环境
1.首先拉取CentOS7.8镜像(笔者之前使用CentOS8进行安装但是CentOS8无法正常安装OpenSSH,折腾了好久后才使用CentOS7进行安装后可以正常安装OpenSSH)
docker pull centos:centos7.8.2003
2.创建固定IP子网
按照集群的架构,创建容器时需要设置固定IP,所以先要在docker使用如下命令创建固定IP的子网.
至于在Docker下的网络模式可以参考博客Docker网络模式详解
docker network create --subnet=172.18.0.0/16 netgroupdocker的子网创建完成之后就可以创建固定IP的容器了。
在docker中创建networks的时候有时候会报ERROR: Pool overlaps with other one on this address space的错误,因目标网段已经存在的原因,通常这发生在将要创建的networks手动指定了subnet网段地址的时候。解决方案有两个:
一是查看已存在的网段是否有容器正在使用,如果没再用了可以删除该网段对应的网卡;
二是修改目标的subnet网段地址。
查看docker网卡
docker network ls删除docker网卡
docker network rm 网卡id查看docker网卡的相关详细信息
docker network inspect 网卡id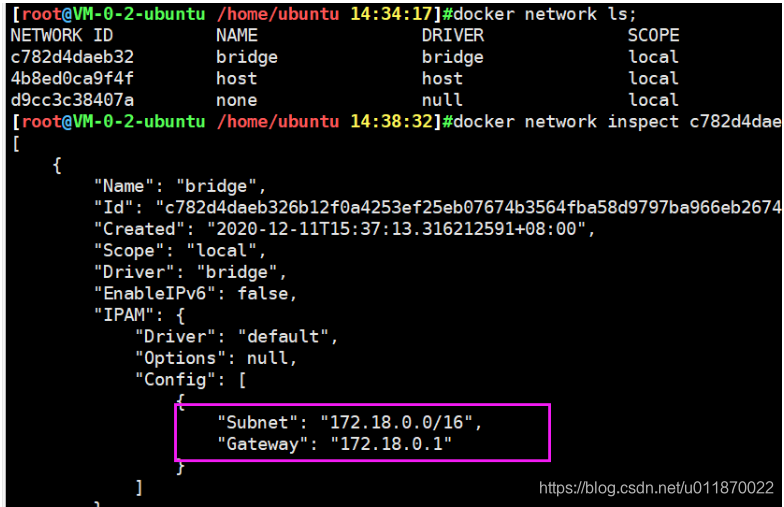
可以发现这个子网IP字段“172.18.0.0/16”已经被占用了,我们需要使用其它新的IP字段来进行创建子网IP
docker network create --driver=bridge --subnet=192.168.0.0/16 --gateway=192.168.0.1 hadoopnetwork
此时已经创建成功
3.docker的子网创建完成之后就可以创建固定IP的容器了
3.1创建容器并制定端口
#hadoop-master
#-p 设置docker映射到容器的端口 后续查看web管理页面使用
docker run -d --privileged=true --name hadoop-master -h hadoop-master -v /hadoop/master/sys/fs/cgroup:/sys/fs/cgroup -p 18088:18088 -p 8970:8970 -p 5581:5581 -p 5582:5582 -p 5580:22 --net hadoopnetwork --ip 192.168.0.2 centos: centos7.8.2003 /usr/sbin/init
#hadoop1
docker run -d --privileged=true --name hadoop1 -h hadoop1 -p 50090:50090 -v /hadoop/hadoop1/sys/fs/cgroup:/sys/fs/cgroup --net hadoopnetwork --ip 192.168.0.3 centos:centos7.8.2003 /usr/sbin/init
#hadoop2
docker run -d --privileged=true --name hadoop2 -h hadoop2 -v /hadoop/hadoop2/sys/fs/cgroup:/sys/fs/cgroup -p 18010:18010 -p 18020:18020 -p 18030:18030 -p 18040:18040 --net hadoopnetwork --ip 192.168.0.4 centos:centos7.8.2003 /usr/sbin/init
##hadoop3
docker run -d --privileged=true --name hadoop3 -h hadoop3 -v /hadoop/hadoop3/sys/fs/cgroup:/sys/fs/cgroup --net hadoopnetwork --ip 192.168.0.5 centos:centos7.8.2003 /usr/sbin/init
3.2修改容器对应的配置文件
有时候刚开始我们不知道需要多少个端口,因此我们可以在容器启动后添加新的端口,即:修改/var/lib/docker/containers/[containerId]目录下,hostconfig.json和config.v2.json 两个配置文件。
3.2.1. 停止容器,停止docker服务
docker stop container_id
systemctl stop docker
3.2. 2. 修改配置文件
3.2.2.1 修改 hostconfig.json文件,修改点一处
进入/var/lib/docker/containers/[containerId]目录下,在 hostconfig.json 里有 "PortBindings":{} 这个配置项,可以改成"PortBindings":{"22/tcp":[{"HostIp":"","HostPort":"5022"}]} 这里 22 是容器端口, 5022 是本地端口
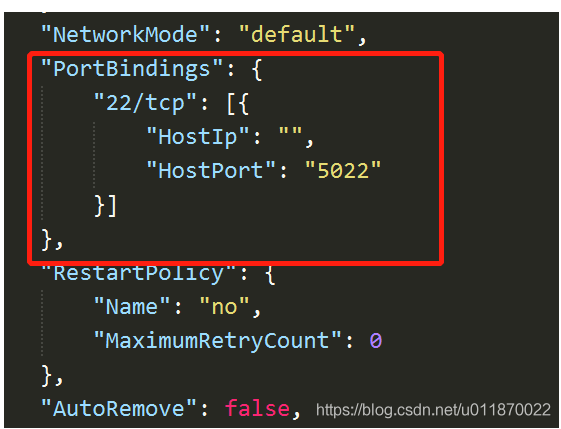
3.2.2.2 修改 config.v2.json 文件,修改点两处
在 config.v2.json 里面添加一个配置项 "ExposedPorts":{"22/tcp":{}}

配置项 "Ports": {} 修改成 "Ports": {"22/tcp": [{"HostIp": "0.0.0.0","HostPort": "5022"}]}
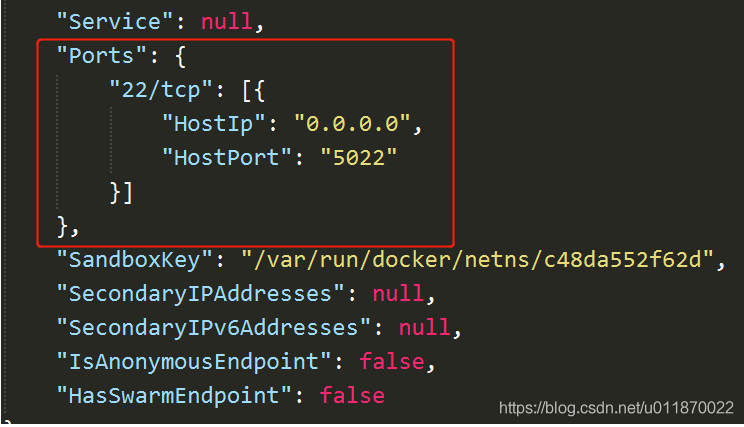
注:修改配置文件前必须先停掉容器及docker服务否则修改将无效。
4.安装OpenSSH免密登录
4.1hadoop-master安装OpenSSH
# 安装Service命令工具
yum -y install initscripts
#安装openssh
[root@hadoop-master /]# yum -y install openssh openssh-server openssh-clients
[root@hadoop-master /]# systemctl start sshd
####ssh自动接受新的公钥
####master设置ssh登录自动添加kown_hosts
[root@hadoop-master /]# vi /etc/ssh/ssh_config
#将原来的StrictHostKeyChecking ask
#设置StrictHostKeyChecking为no
#保存
[root@hadoop-master /]# systemctl restart sshd4.2分别对slaves(hadoop1,hadoop2,hadoop3)安装OpenSSH
#安装openssh
[root@hadoop1 /]#yum -y install openssh openssh-server openssh-clients
[root@hadoop1 /]# systemctl start sshd4.3hadoop-master公钥分发
在master机上执行
ssh-keygen -t rsa并一路回车,完成之后会生成~/.ssh目录,目录下有id_rsa(私钥文件)和id_rsa.pub(公钥文件),再将id_rsa.pub重定向到文件authorized_keys
ssh-keygen -t rsa
#一路回车然后将公钥导入
[root@hadoop-master /]# cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys(注意:所有节点均要配置,方法同上,此处略)
然后将每个节点的公钥都复制到authorized_keys,也就是说每个节点的authorized_keys 文件中存储的公钥都是4个而且是一样的,可以采用下面的命令来进行复制,也可以自己手动复制
将四个容器中的文件复制到本地宿主机
[root@VM-0-2-ubuntu /hadoop 17:25:13]#docker cp hadoop1:/root/.ssh/authorized_keys /hadoop/authorized_keys_hadoop1
[root@VM-0-2-ubuntu /hadoop 17:25:13]#docker cp hadoop2:/root/.ssh/authorized_keys /hadoop/authorized_keys_hadoop2
[root@VM-0-2-ubuntu /hadoop 17:25:27]# docker cp hadoop3:/root/.ssh/authorized_keys /hadoop/authorized_keys_hadoop3
[root@VM-0-2-ubuntu /hadoop 17:25:35]# docker cp hadoop-master:/root/.ssh/authorized_keys /hadoop/authorized_keys_hadoop-master这时候在宿主机的 /hadoop目录下有四个公钥:
将这四个文件整合成一个文件
[root@VM-0-2-ubuntu /hadoop 17:26:41]# cat authorized_keys_hadoop-master authorized_keys_hadoop1 authorized_keys_hadoop2 authorized_keys_hadoop3 > authorized_keys再将整合后的文件复制到三个容器中
[root@VM-0-2-ubuntu /hadoop 17:27:11]#docker cp /hadoop/authorized_keys hadoop1:/root/.ssh/authorized_keys
[root@VM-0-2-ubuntu /hadoop 17:27:44]#docker cp /hadoop/authorized_keys hadoop2:/root/.ssh/authorized_keys
[root@VM-0-2-ubuntu /hadoop 17:29:01]#docker cp /hadoop/authorized_keys hadoop3:/root/.ssh/authorized_keys
[root@VM-0-2-ubuntu /hadoop 17:29:05]#docker cp /hadoop/authorized_keys hadoop-master:/root/.ssh/authorized_keys进入hadoop1查看一下
[hadoop@bogon ~]$ docker exec -it hadoop1 bash
bash-4.1# cat root/.ssh/authorized_keys 
可以发现,在hadoop-master中使用 ssh命令登录到hadoop1中是直接不需要密码就可以登录了的。
4.4Ansible安装
[root@hadoop-master /]# yum -y install epel-release
[root@hadoop-master /]# yum -y install ansible
#这样的话ansible会被安装到/etc/ansible目录下此时我们再去编辑ansible的hosts文件
vi /etc/ansible/hosts
[hadoop]
hadoop-master
hadoop1
hadoop2
hadoop3
[master]
hadoop-master
[slaves]
hadoop1
hadoop2
hadoop3
配置docker容器hosts
由于/etc/hosts文件在容器启动时被重写,直接修改内容在容器重启后不能保留,为了让容器在重启之后获取集群hosts,使用了一种启动容器后重写hosts的方法。需要在~/.bashrc中追加以下指令:
vim ~/.bashrc:>/etc/hosts
cat >>/etc/hosts<<EOF
192.168.0.2 hadoop-master
192.168.0.3 hadoop1
192.168.0.4 hadoop2
192.168.0.5 hadoop3
EOF特别提示,不要写入多余的host映射进来,你有多少个机器就写多少个ip和域名映射对进来,不要多写,否则后面启动集群时候会出现问题,切记切记!
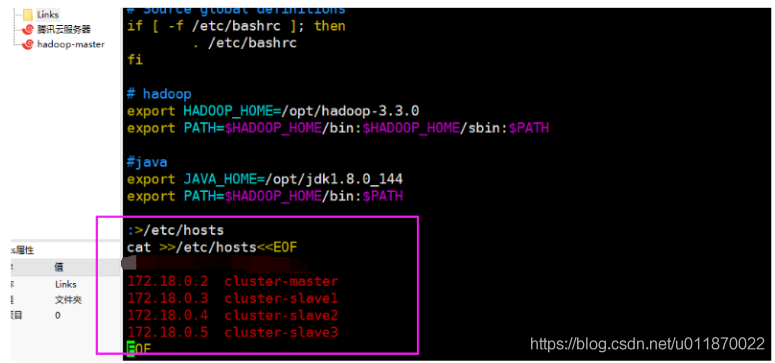
source ~/.bashrc使配置文件生效,可以看到/etc/hosts文件已经被改为需要的内容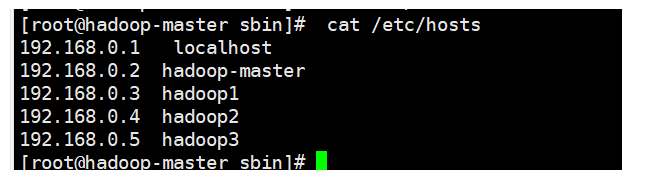
用ansible分发.bashrc至集群slave下使每个机器都有同样的hosts
ansible hadoop -m copy -a "src=~/.bashrc dest=~/"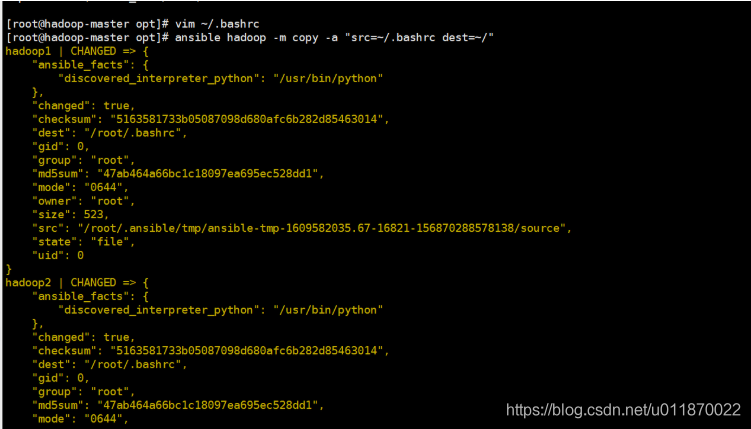

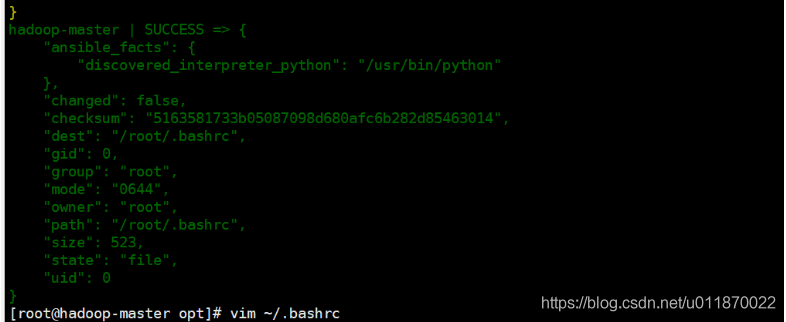

这时候每个从机都有同样的hosts.注意,如果没有显示完整的hosts则说明是分法失败,需要自己手动进入每个机器中,键入:
:>/etc/hosts
cat >>/etc/hosts<<EOF
192.168.0.2 hadoop-master
192.168.0.3 hadoop1
192.168.0.4 hadoop2
192.168.0.5 hadoop3
EOF然后更新一下:
source ~/.bashrc5.软件环境配置
| hadoop-master | hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|---|
| HDFS | nameNode,DataNode | SecondaryNameNode,DataNode | DataNode | DataNode |
| YARNNodeManager | NodeManager | NodeManager | ResourceManager,NodeManager | historyServer |
5.1将hadoop-3.3.0.tar.gz和jdk-8u144-linux-x64.tar.gz发送到服务器
首先将hadoop-3.3.0.tar.gz和jdk-8u144-linux-x64.tar.gz发送到服务器,具体文件夹自己指定,笔者这里指定发送到服务器的/opt下:

然后从服务器中将这两个文件复制到容器hadoop-master中的/opt目录中去:
[root@VM-0-2-ubuntu /opt 23:44:23]#docker cp hadoop-3.3.0.tar.gz hadoop-master:/opt
[root@VM-0-2-ubuntu /opt 23:45:58]#docker cp jdk-8u144-linux-x64.tar.gz hadoop-master:/opt5.2然后进入hadoop-master中:
docker exec -it hadoop-master bash
可以发现 hadoop-3.3.0.tar.gz和jdk-8u144-linux-x64.tar.gz已经复制到/opt目录中
5.3解压
首先解压JDK:
tar -xzvf jdk-8u144-linux-x64.tar.gz 其次解压Hadoop:
tar -xzvf hadoop-3.3.0.tar.gz 并给Hadoop创建链接文件:
ln -s hadoop-3.2.0 hadoop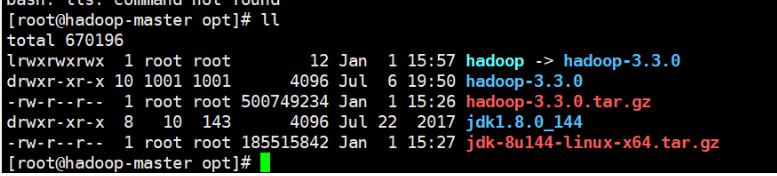
# hadoop
export HADOOP_HOME=/opt/hadoop-3.3.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#java
export JAVA_HOME=/opt/jdk1.8.0_144
export PATH=$HADOOP_HOME/bin:$PATH
使文件生效:
source ~/.bashrc在 /etc/profile中添加:
export JAVA_HOME=/opt/jdk1.8.0_144
export PATH=:$JAVA_HOME/bin:$PATH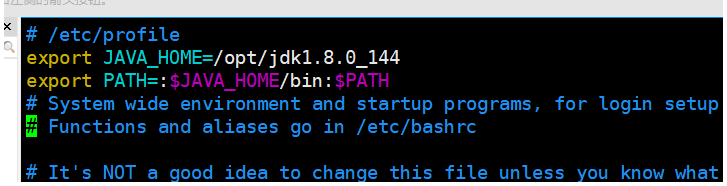
使用命令将其生效
source /etc/profile5.4hadoop运行所需配置文件首先进入$HADOOP_HOME/etc/hadoop/目录
cd $HADOOP_HOME/etc/hadoop/常用的端口配置
HDFS端口
| 参数 | 描述 | 默认 | 配置文件 | 例子值 |
|---|---|---|---|---|
| fs.default.name namenode | namenode RPC交互端口 | 8020 | core-site.xml | hdfs://master:8020/ |
| dfs.http.address | NameNode web管理端口 | 50070 | hdfs- site.xml | 0.0.0.0:50070 |
| dfs.datanode.address | datanode 控制端口 | 50010 | hdfs -site.xml | 0.0.0.0:50010 |
| dfs.datanode.ipc.address | datanode的RPC服务器地址和端口 | 50020 | hdfs-site.xml | 0.0.0.0:50020 |
| dfs.datanode.http.address | datanode的HTTP服务器和端口 | 50075 | hdfs-site.xml | 0.0.0.0:50075 |
MR端口
| 参数 | 描述 | 默认 | 配置文件 | 例子值 |
|---|---|---|---|---|
| mapred.job.tracker | job-tracker交互端口 | 8021 | mapred-site.xml | hdfs://master:8021/ |
| job | tracker的web管理端口 | 50030 | mapred-site.xml | 0.0.0.0:50030 |
| mapred.task.tracker.http.address | task-tracker的HTTP端口 | 50060 | mapred-site.xml | 0.0.0.0:50060 |
其它端口
| 参数 | 描述 | 默认 | 配置文件 | 例子值 |
|---|---|---|---|---|
| dfs.secondary.http.address | secondary NameNode web管理端口 | 50090 | hdfs-site.xml | 0.0.0.0:50090 |

5.4.1修改workers文件
修改workers(注意hadoop3.X版本是workers文件,3.x版本以下是slaves文件)文件,写入以下内容:
hadoop-master
hadoop1
hadoop2
hadoop3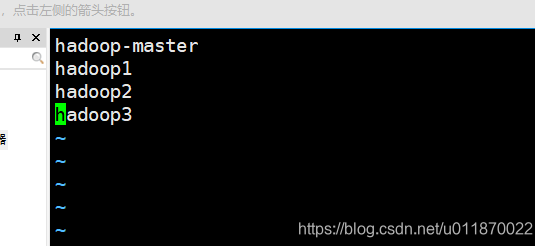
5.4.2修改core-site.xml
vim core-site.xml<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<!--1、fs.default.name:默认的文件系统,一般将其改为hdfs。-->
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>4320</value>
</property>5.4.3修改修改hdfs-site.xml
vim hdfs-site.xml <configuration>
<!-- 指定secondary的访问地址和端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:50090</value>
</property>
<!-- 指定namenode的访问地址和端口 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop-master:5581</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>4</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>staff</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 指定namenode日志文件的存放目录 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>/hadoop/logs/namenode</value>
</property>
<!-- 设置一个文件切片的大小:128M-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>5.4.4修改mapred-site.xml
vim mapred-site.xml<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>hadoop-master:50030</value>
</property>
<property>
<name>mapreduce.jobhisotry.address</name>
<value>hadoop-master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-master:8970</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/jobhistory/done</value>
</property>
<property>
<name>mapreduce.intermediate-done-dir</name>
<value>/jobhisotry/done_intermediate</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>5.4.5修改yarn-site.xml
vim yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop2:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop2:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop2:18025</value>
</property> <property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop2:18020</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop2:18010</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/hadoop/logs/remoteApiLogs</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
</configuration>5.5打包hadoop 向slaves分发
tar -cvf hadoop-dis.tar hadoop hadoop-3.3.05.6使用ansible-playbook分发.bashrc和hadoop-dis.tar至slave主机
创建shell文件写入如下内容:
---
- hosts: hadoop
tasks:
- name: copy .bashrc to slaves
copy: src=~/.bashrc dest=~/
notify:
- exec source
- name: copy profile to slaves
copy: src=/etc/profile dest=/etc/
notify:
- exec profile
- name: copy hadoop-dis.tar to slaves
unarchive: src=/opt/hadoop-dis.tar dest=/opt
handlers:
- name: exec source
shell: source ~/.bashrc
- name: exec profile
shell: source /etc/profile将以上yaml保存为hadoop-dis.yaml)并执行
ansible-playbook hadoop-dis.yamlhadoop-dis.tar会自动解压到slave主机的/opt目录下。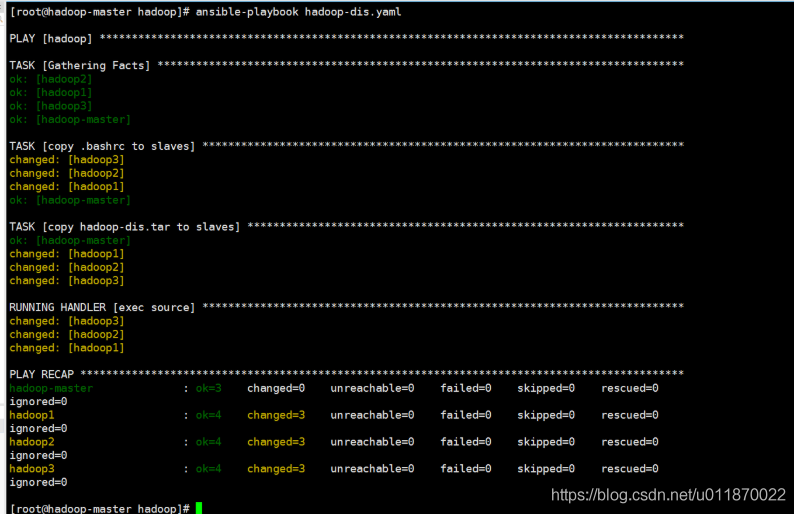
5.7为了方便修改配置文件,因此 写了一个脚本,每次在Hadoop-master上更新了Hadoop的etc的配置文件后就同步分发到从机上
使用vim 创建一个 hadoop-dis-etcconfig.yaml文件,键入以下内容:
---
- hosts: hadoop
tasks:
- name: copy Hadoop-3.3.3的配置文件 to slaves
copy: src=/opt/hadoop-3.3.0/etc/hadoop dest=/opt/hadoop-3.3.0/etc/
- name: copy profile to slaves
copy: src=/etc/profile dest=/etc/
notify:
- exec source
handlers:
- name: exec source
shell: source /etc/profile 将以上yaml保存为hadoop-dis-etcconfig.yaml并执行
ansible-playbook hadoop-dis-etcconfig.yaml5.8为了方便修改配置文件,因此 写了一个脚本,每次在Hadoop-master上更新了~/.bashrc的配置文件后就同步分发到从机上
使用vim 创建一个hodoop-dist-bashrc.yaml文件,键入以下内容:
---
- hosts: hadoop
tasks:
- name: copy .bashrc to slaves
copy: src=~/.bashrc dest=~/
notify:
- exec source
handlers:
- name: exec source
shell: source ~/.bashrc将以上yaml保存为hodoop-dist-bashrc.yaml并执行
ansible-playbook hodoop-dist-bashrc.yaml6.Hadoop 启动
6.1格式化namenode
hadoop namenode -format如果看到storage format success等字样,即可格式化成功
6.2出现“Attempting to operate on hdfs namenode as root”的解决办法
1、master,slave都需要修改start-dfs.sh,stop-dfs.sh,start-yarn.sh,stop-yarn.sh四个文件
2、如果你的Hadoop是另外启用其它用户来启动,记得将root改为对应用户
HDFS格式化后启动dfs出现以下错误:
[root@master sbin]# ./start-dfs.sh
Starting namenodes on [master]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [slave1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
1234567891011在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root6.3启动集群
cd $HADOOP_HOME/sbin
start-dfs.sh
start-yarn.sh
#注意,jobhistory需要用Start historyServer命令起动
mr-jobhistory-daemon.sh start historyserver#或者使用 start-all.sh
start-all.sh
mr-jobhistory-daemon.sh start historyserver启动后可使用jps命令查看是否启动成功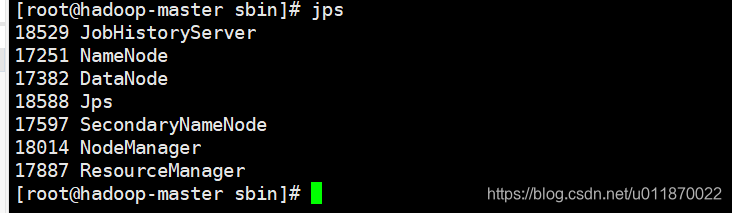
访问(其中host是你的主机ip地址,端口需要在安全规则组中开放)
http://host:18010
http://host:5581
http://host:8970
http://host:50090

7.故障解决File /input.COPYING could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and 0 node(s) are excluded in this operation.
搭建好平台后,通过java代码或使用hadoop fs -put向hadoop中上传文件时,报以上错误。报错信息大概的意思是节点没有启动,但是使用jps又能查看到节点信息,如下图所示。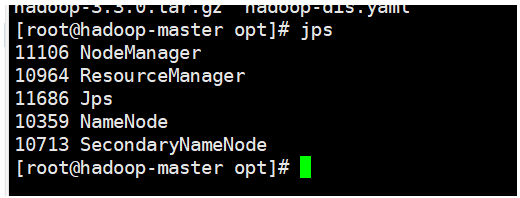
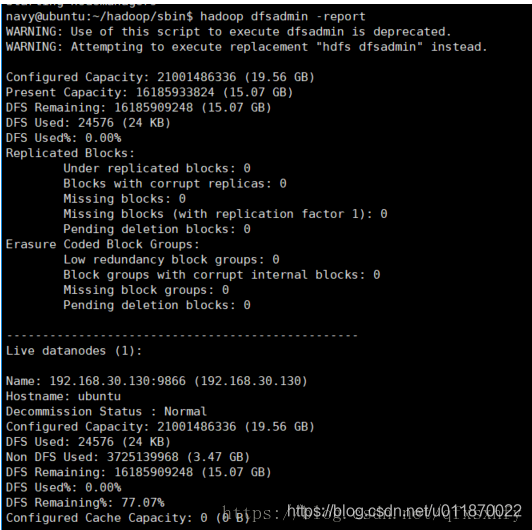
使用hadoop dfsadmin -report命令查看磁盘使用情况,发现都是空的。如下图所示: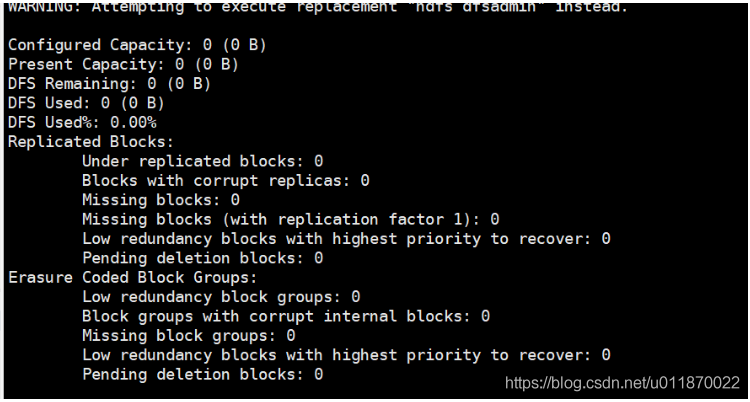
这个问题一般是由于使用hadoop namenode -format 格式化多次,导致spaceID不一致造成的,解决方法如下:
1、 停止集群所有的服务。指令为:stop-all.sh
2、删除hdfs中配置的data目录下的所有文件(级core-site.xml中配置的hadoop.tmp.dir)。指令为:rm -rf /hadoop/tmp/*
3、重新格式化namenode。指令为:hadoop namenode -format
4、重新启动hadoop集群。指令为:start-all.sh
再使用hadoop dfsadmin -report查看时,显示如下信息:
[
到此,一般来说问题应该就解决了。但是,如果这样还没有解决,这回好就该去查看一下日志,查看一下里面的日志,如果发现有端口占用问题或者ip绑定问题

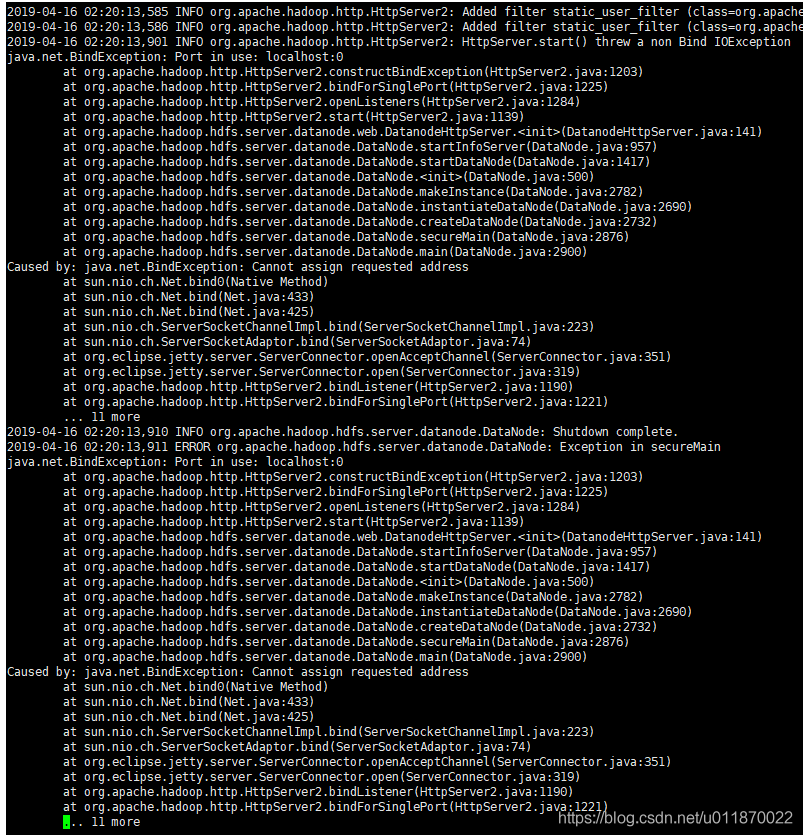
解决方法:
(1)检查网络问题。
此次问题出现原因是由于本人切换至公司外网,导致网络请求失败。
(2)检查/etc/hosts文件的配置是否有问题。
在hosts文件中删除多余的IP与主机名的对应关系,之后就成为了如下的样子:
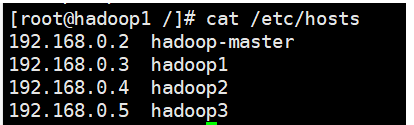
8.在Docker中的CentOS7.8中进行Hadoop-3.3.0源码编译
8.1 前期准备工作
注意:采用root角色编译,减少文件夹权限出现问题
- jar包准备(hadoop-3.3.0-src.tar.gz 源码、JDK8、maven-3.6.3、ant-1.9.15 、protobuf-3.14.0)
(1)hadoop-3.3.0-src.tar.gz
(2)jdk-8u144-linux-x64.tar.gz
(3)apache-ant-1.9.15-bin.tar.gz(build工具,打包用的)
(4)apache-maven-3.6.3-bin.tar.gz
(5)protobuf-3.14.0.tar.gz(序列化的框架)
首先将这些文件从本地上传到服务器宿主机,然后使用 docker cp fileSrc 容器名:dest 命令将这些文件拷贝到容器中。比如说将hadoop-3.3.0-src.tar.gz从宿主机的 /opt目录下拷贝到hadoop-master容器的/opt目录下:
docker cp /opt/hadoop-3.3.0-src.tar.gz hadoop-master:/opt其它文件类似操作,将这些文件都拷贝到容器hadoop-master中进行。
8.2 java包安装
注意:所有操作必须在root用户下完成.
首先进入hadoop-master容器:
docker exec -it hadoop-master bash然后入存放文件的目录:
cd /opt8.2.1JDK解压、配置环境变量 JAVA_HOME和PATH
[root@hadoop-master opt] # tar -zxf jdk-8u144-linux-x64.tar.gz -C /opt8.2.2将jdk的环境变量加入到profile中:
[root@hadoop-master opt]# vi /etc/profile#JAVA_HOME:
export JAVA_HOME=/opt/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin[root@hadoop-master opt]#source /etc/profile8.2.3验证命令:java -version
如果出现Java的版本信息则安装成功。
8.3Maven解压、配置 MAVEN_HOME和PATH
8.3.1解压
[root@hadoop-master opt]# tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt8.3.2在setting.xml中配置阿里云镜像源,方便下载依赖文件:
[root@hadoop-master apache-maven-3.6.3]# vi conf/settings.xml<mirrors>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>8.3.3配置maven的根路径
[root@hadoop-master apache-maven-3.6.3]# vi /etc/profile#MAVEN_HOME
export MAVEN_HOME=/opt/apache-maven-3.6.3
export PATH=$PATH:$MAVEN_HOME/bin更新profile文件
[root@hadoop-master opt]#source /etc/profile验证命令:
mvn -version
8.4ant解压、配置 ANT _HOME和PATH
8.4.1解压
[root@hadoop-master opt]# tar -zxvf apache-ant-1.9.15-bin.tar.gz -C /opt8.4.2添加根路径
[root@hadoop-master apache-ant-1.9.15]# vi /etc/profile#ANT_HOME
export ANT_HOME=/opt/apache-ant-1.9.15
export PATH=$PATH:$ANT_HOME/bin8.4.3更新profile文件
[root@hadoop-master opt]#source /etc/profile8.4.4验证
ant -version
8.5安装 glibc-headers 和 g++ 命令如下
[root@hadoop-master apache-ant-1.9.15]# yum install glibc-headers
[root@hadoop-master apache-ant-1.9.15]# yum install gcc-c++8.6安装make和cmake
[root@hadoop-master apache-ant-1.9.15]# yum install make
[root@hadoop-master apache-ant-1.9.15]# yum install cmake8.7安装
8.7.1解压protobuf ,进入到解压后protobuf主目录,/opt/protobuf-3.14.0,然后相继执行命令
[root@hadoop-master opt]# tar -zxvf protobuf-3.14.0.tar.gz -C /opt
[root@hadoop-master opt]# cd /opt/protobuf-3.14.0/
[root@hadoop-master protobuf-3.14.0]# ./configure
[root@hadoop-master protobuf-3.14.0]# make
[root@hadoop-master protobuf-3.14.0]# make check
[root@hadoop-master protobuf-3.14.0]# make install
[root@hadoop-master protobuf-3.14.0]# ldconfig
8.7.2添加根路径
[root@hadoop-master protobuf-3.14.0]# vi /etc/profile#LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/opt/protobuf-3.14.0
export PATH=$PATH:$LD_LIBRARY_PATH更新profile文件
[root@hadoop-master opt]#source /etc/profile验证命令:protoc --version
8.8安装openssl库
[root@hadoop-master opt]#yum install openssl-devel8.9安装 ncurses-devel库
[root@hadoop-master opt]#yum install ncurses-devel到此,编译工具安装基本完成。
8.10 编译源码
8.10.1解压源码到/opt/目录
[root@hadoop-master opt]# tar -zxvf hadoop-3.3.0-src.tar.gz -C /opt/
8.10.2. 进入到hadoop源码主目录
[root@hadoop-masterhadoop-3.3.0-src]#dir
8.10.3. 通过maven执行编译命令
[root@hadoop-master hadoop-3.3.0-src]#mvn package -Pdist,native -DskipTests -Dtar等待时间30分钟左右,最终成功是全部SUCCESS,如图2-42所示。

8.11成功的64位hadoop包在/opt/hadoop-3.3.0-src/hadoop-dist/target下
[root@hadoop-master target]# 参考文献:

