









1.设计题目与要求
1.1设计题目:内核定时器
1.2设计要求:
通过研究内核的时间管理算法,学习内核源代码;然后应用这些知识并且使用“信号”建立一种用户空间机制来测量一个多线程程序的执行时间。
2.总的设计思想及系统平台、语言、工具
2.1 设计思想:
2.1.1Linux内核的描述
操作系统是一个用来和硬件打交道并为用户程序提供一个有限服务集的低级支撑软件。一个计算机系统是一个硬件和软件的共生体,它们互相依赖,不可分割。计算机的硬件,含有外围设备、处理器、内存、硬盘和其他的电子设备组成计算机的发动机。但是没有软件来操作和控制它,自身是不能工作的。完成这个控制工作的软件就称为操作系统,在Linux的术语中被称为“内核”,也可以称为“核心”。Linux内核的主要模块(或组件)分以下几个部分:存储管理、CPU和进程管理、文件系统、设备管理和驱动、网络通信,以及系统的初始化(引导)、系统调用等。
内核是一个操作系统的核心。它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性。
2.1.2Linux 内核定时器
内核定时器是内核用来控制在未来某个时间点(基于jiffies)调度执行某个函数的一种机制,其实现位于 和 kernel/timer.c 文件中。被调度的函数肯定是异步执行的,它类似于一种“软件中断”,而且是处于非进程的上下文中,所以调度函数必须遵守以下规则:1) 没有 current 指针、不允许访问用户空间。因为没有进程上下文,相关代码和被中断的进程没有任何联系。2) 不能执行休眠(或可能引起休眠的函数)和调度。3) 任何被访问的数据结构都应该针对并发访问进行保护,以防止竞争条件。内核定时器的调度函数运行过一次后就不会再被运行了(相当于自动注销),但可以通过在被调度的函数中重新调度自己来周期运行。在SMP系统中,调度函数总是在注册它的同一CPU上运行,以尽可能获得缓存的局域性。
2.1.3多线程
多线程(multithreading),是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。具有这种能力的系统包括对称多处理机、多核心处理器以及芯片级多处理或同时多线程处理器。在一个程序中,这些独立运行的程序片段叫作“线程”(Thread),利用它编程的概念就叫作“多线程处理”。
多线程的测试:
新建一个ThreadDemo.cpp文件,进入vim ThreadDemo.cpp然后输入以下代码:
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_THREADS 5
void *PrintHello(void *threadid)
{
// 对传入的参数进行强制类型转换,由无类型指针变为整形数指针,然后再读取
int tid = *((int*)threadid);
cout << "Hello Runoob! 线程 ID, " << tid << endl;
pthread_exit(NULL);
}
int main ()
{
pthread_t threads[NUM_THREADS];
int indexes[NUM_THREADS];// 用数组来保存i的值
int rc;
int i;
for( i=0; i < NUM_THREADS; i++ ){
cout << "main() : 创建线程, " << i << endl;
indexes[i] = i; //先保存i的值
// 传入的时候必须强制转换为void* 类型,即无类型指针
rc = pthread_create(&threads[i], NULL,
PrintHello, (void *)&(indexes[i]));
if (rc){
cout << "Error:无法创建线程," << rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}保存后退出。然后编译运行: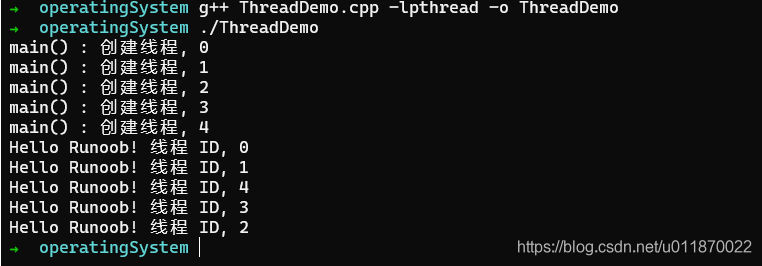

通过观察可以发现,每次重新运行的时候,线程先后输出的结果都不一样,这说明线程间存在抢夺CPU资源的情况
2.1.4动态内核定时器机制的原理
Linux是怎样为其内核定时器机制提供动态扩展能力的呢?其关键就在于“定时器向量”的概念。所谓“定时器向量”就是指这样一条双向循环定时器队列(对列中的每一个元素都是一个timer_list结构):
struct timer_list {
struct list_head list;
unsigned long expires;
unsigned long data;
void (*function)(unsigned long);
};对列中的所有定时器都在同一个时刻到期,也即对列中的每一个timer_list结构都具有相同的expires值。显然,可以用一个timer_list结构类型的指针来表示一个定时器向量。显然,定时器expires成员的值与jiffies变量的差值决定了一个定时器将在多长时间后到期。在32位系统中,这个时间差值的最大值应该是0xffffffff。因此如果是基于“定时器向量”基本定义,内核将至少要维护0xffffffff个timer_list结构类型的指针,这显然是不现实的。另一方面,从内核本身这个角度看,它所关心的定时器显然不是那些已经过期而被执行过的定时器(这些定时器完全可以被丢弃),也不是那些要经过很长时间才会到期的定时器,而是那些当前已经到期或者马上就要到期的定时器(注意!时间间隔是以滴答次数为计数单位的)。基于上述考虑,并假定一个定时器要经过interval个时钟滴答后才到期(interval=expires-jiffies),则Linux采用了下列思想来实现其动态内核定时器机制:对于那些0≤interval≤255的定时器,Linux严格按照定时器向量的基本语义来组织这些定时器,也即Linux内核最关心那些在接下来的255个时钟节拍内就要到期的定时器,因此将它们按照各自不同的expires值组织成256个定时器向量。而对于那些256≤interval≤0xffffffff的定时器,由于他们离到期还有一段时间,因此内核并不关心他们,而是将它们以一种扩展的定时器向量语义(或称为“松散的定时器向量语义”)进行组织。
2.1.5 内核动态定时器机制的实现
在内核动态定时器机制的实现中,有三个操作是非常重要的:
(1)将一个定时器插入到它应该所处的定时器向量中。
(2)定时器的迁移,也即将一个定时器从它原来所处的定时器向量迁移到另一个定时器向量中。
(3)扫描并执行当前已经到期的定时器。
步骤:
2.1.5.1动态定时器机制的初始化。
2.1.5.2 动态定时器的时钟滴答基准timer_jiffies。
2.1.5.3对内核动态定时器链表的保护。
2.1.5.4将一个定时器插入到链表中。
2.1.5.5修改一个定时器的expires值。
2.1.5.6 删除一 定时器迁移操作个定时器。
2.1.5.7 定时器迁移操作。
2.1.6 Linux 信号signal处理机制
软中断信号(signal,又简称为信号)用来通知进程发生了异步事件。在软件层次上是对中断机制的一种模拟,在原理上,一个进程收到一个信号与处理器收到一个中断请求可以说是一样的。信号是进程间通信机制中唯一的异步通信机制,一个进程不必通过任何操作来等待信号的到达,事实上,进程也不知道信号到底什么时候到达。进程之间可以互相通过系统调用kill发送软中断信号。内核也可以因为内部事件而给进程发送信号,通知进程发生了某个事件。信号机制除了基本通知功能外,还可以传递附加信息。
收到信号的进程对各种信号有不同的处理方法。处理方法可以分为三类:
第一种是类似中断的处理程序,对于需要处理的信号,进程可以指定处理函数,由该函数来处理。
第二种方法是,忽略某个信号,对该信号不做任何处理,就象未发生过一样。
第三种方法是,对该信号的处理保留系统的默认值,这种缺省操作,对大部分的信号的缺省操作是使得进程终止。进程通过系统调用signal来指定进程对某个信号的处理行为。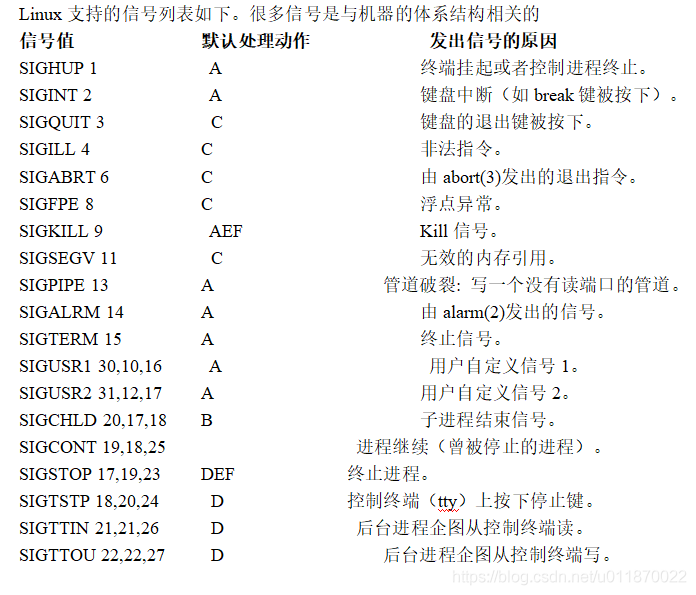
处理动作一项中的字母含义如下。
A 缺省的动作是终止进程。
B 缺省的动作是忽略此信号,将该信号丢弃,不做处理。
C 缺省的动作是终止进程并进行内核映像转储(dump core),内核映像转储是指将进程数据在内存的映像和进程在内核结构中的部分内容以一定格式转储到文件系统,并且进程退出执行,这样做的好处是为程序员提供了方便,使得他们可以得到进程当时执行时的数据值,允许他们确定转储的原因,并且可以调试他们的程序。
D 缺省的动作是停止进程,进入停止状况以后还能重新进行下去,一般是在调试的过程中(例如ptrace系统调用)。
E 信号不能被捕获。
F 信号不能被忽略。
信号的测试
创建SignalDemo.cpp文件,然后使用vim SignalDemo.cpp进入输入以下代码:
#include <iostream>
#include <csignal>
#include <unistd.h>
using namespace std;
void signalHandler( int signum )
{
cout << "Interrupt signal (" << signum << ") received.\n";
// 清理并关闭
// 终止程序
exit(signum);
}
int main ()
{
// 注册信号 SIGINT 和信号处理程序
signal(SIGINT, signalHandler);
while(1){
cout << "Going to sleep...." << endl;
sleep(1);
}
return 0;
}保存后退出,然后进行编译: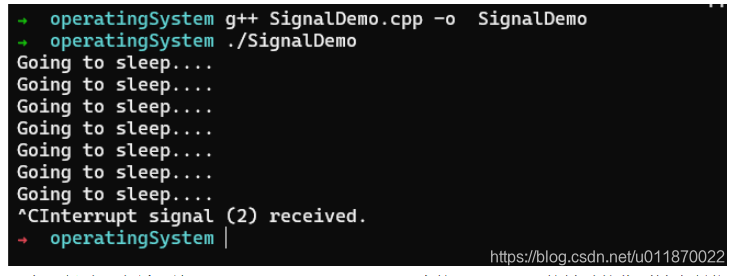
程序运行时一直循环输出 “going to sleep ….”,当按下Ctrl + C 按键时接收到键中断信号SIGINT 2,从而该程序结束运行。
2.1.7测量一个多线程程序的执行时间的设计原理
进程和线程都是由操作系统所体会的程序运行的基本单元,系统利用该基本单元实现系统对应用的并发性。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。linux是一个具有保护模式的操作系统。它一直工作在i386 cpu的保护模式之下。内存被分为两个单元: 内核区域和用户区域。一般地,在使用虚拟内存技术的多任务系统上,内核和应用有不同的地址空间,因此,在内核和应用之间以及在应用与应用之间进行数据交换需要专门的机制来实现。
内核定时器是管理内核时间的基础,用来计算流逝的时间,它以某种频率(节拍率)自行触发时钟中断。内核定时器在时钟中断发生后,作为软中断在下半部的上下文钟执行的。所有的定时器结构都以链表的形式存储。时钟中断发生后,内核按链表顺序依次执行。
一般来说,定时器在超时后会立即执行,但是也有可能被推迟到下一个时钟节拍才能运行,所以不能用定时器来实现硬实时的操作。又因为内核定时器发生在软中断中,因此,定时器执行函数不能够睡眠,也不能够持有信号量。如果对硬件的访问需要使用信号量同步,或者可能睡眠(比如需要调用kmalloc内存分配,但是由于某种原因不能使用GFP_ATOMIC标志),就不能直接通过定时器来实现了。一个变通的做法是在内核定时器执行函数里调用工作队列,在工作队列处理函数中实现对硬件的访问。
本次的实验使用三个线程,一个主线程main,另外两个子线程。我们就是在主线程main中测量两个子线程同时运行所需要的时间。为了方便测试,每个线程都倒计时5s,以此来更加直观看到测量的时间。
2.2 系统平台:
阿里云服务器的一台Linux主机且有超级用户权限
2.3 编程工具:
VIM编辑器
3.数据结构与模块说明(功能与流程图)
3.1本程序的基本数据结构:
3.1.1 timeval结构体,位于C++的 time.h文件中
struct timeval{
long int tv_sec; // 秒数
long int tv_usec; // 微秒数
}它获得的时间精确到微秒(1e-6 s)量级。在一段代码前后分别使用gettimeofday可以计算代码执行时间:
struct timeval tv_begin, tv_end;
gettimeofday(&tv_begin, NULL);
gettimeofday(& tv_end, NULL);
然后我们通过前后时间进行相减就可以获取这段时间了。
3.1.2 创建线程的函数 pthread_create(),位于头文件pthread.h中
int pthread_create(pthread_t *restrict tidp,
const pthread_attr_t *restrict attr,
void *(*start_rtn)(void),
void *restrict arg
);第一个参数为指向线程标识符的指针。
第二个参数用来设置线程属性。
第三个参数是线程运行函数的起始地址。
最后一个参数是运行函数的参数。
3.1.3 创建线程的函数 pthread_join(pthread_t thread, void **value_ptr),位于头文件pthread.h中
3.1.3.1参数解释:
thread:等待退出线程的线程号。
value_ptr:退出线程的返回值
3.1.3.2作用
在Linux中,新建的线程并不是在原先的进程中,而是系统通过一个系统调用clone()。该系统调用clone() copy了一个和原先进程完全一样的进程,并在这个进程中执行线程函数。不过这个copy过程和fork不一样。 copy后的进程和原先的进程共享了所有的变量,运行环境。这样,原先进程中的变量变动在copy后的进程中便能体现出来。
那么pthread_join函数有什么用呢?pthread_join使一个线程等待另一个线程结束。代码中如果没有pthread_join主线程会很快结束从而使整个进程结束,从而使创建的线程没有机会开始执行就结束了。加入pthread_join后,主线程会一直等待直到等待的线程结束自己才结束,使创建的线程有机会执行。所有线程都有一个线程号,也就是Thread ID。其类型为pthread_t。通过调用pthread_self()函数可以获得自身的线程号。
如果你的主线程,也就是main函数执行的那个线程,在你其他线程退出之前就已经退出,那么带来的bug则不可估量。通过pthread_join函数会让主线程阻塞,直到所有线程都已经退出。
3.1.4void* task(void *args)
子线程要执行的任务函数
3.1.5 int pthread()
创建子线程并让主线程进入阻塞状态
3.2本程序算法:
3.2.1首先程序从主线程main开始执行函数,记录开始时间tv_start.
3.2.2 main调用pthread()函数开始创建子线程1和子线程2
3.2.3子线程1和子线程2开始执行各自的task(void* args)函数,主线程main进入阻塞等待子线程1和子线程2执行结束。
3.2.4子线程1和子线程2执行任务结束,主线程main恢复执行,记录子线程结束运行时间tv_end。
3.2.5计算子线程运行的时间 tv_end - tv_start.
3.33.3程序流程图:
3.4本程序的基本数据结构:

4.源程序
测试多线程运行用时:
KernelCountTime.cpp文件
#include <sys/time.h>
#include <pthread.h>
#include<unistd.h>
#include <iostream>
using namespace std;
void* task(void *args){
//倒计时五秒
int sec = 5 ;
//获取线程的编号
int num =*(int*)args;
while(sec > 0){
//休眠一秒钟再运行
sleep(1);
sec--;
printf("子线%d程倒计时%d秒\n",num,sec);
}
}
int pthread(){
//声明一个pthread_t 变量线程1
pthread_t id1;
//线程2
pthread_t id2;
//线程创建的结果标志
int result;
int num1 =1;
int num2 =2;
//创建一个线程1,运行任务函数 task()
result=pthread_create(&id1,NULL,task,(int*)&num1);
if(result != 0){
printf("Create pthread error!\n");
exit(1);
}
//创建一个线程2,运行任务函数 task()
result=pthread_create(&id2,NULL,task,(int*)&num2);
if(result != 0){
printf("Create pthread error!\n");
exit(1);
}
//打印主线程
for(int i=0;i<3;i++){
printf("This is the main process.\n");
}
//线程id为id的子线程进入等待
pthread_join(id1,NULL);
pthread_join(id2,NULL);
return 0;
}
main(){
struct timeval tpstart,tpend;
/*申请struct timeval的变量,tv_sec返回的是秒数,tv_usec返回的是微秒数*/
float timeuse;
//获取开始时的时间
gettimeofday(&tpstart,NULL);
pthread();
//获取结束的时间
gettimeofday(&tpend,NULL);
//计算线程运行的总的使用的时间
timeuse=1000000*(tpend.tv_sec-tpstart.tv_sec)+ tpend.tv_usec-tpstart.tv_usec;
timeuse/=1000000;
printf("Used Time:%f sec\n",timeuse);
exit(0);
}5.运行结果与运行情况
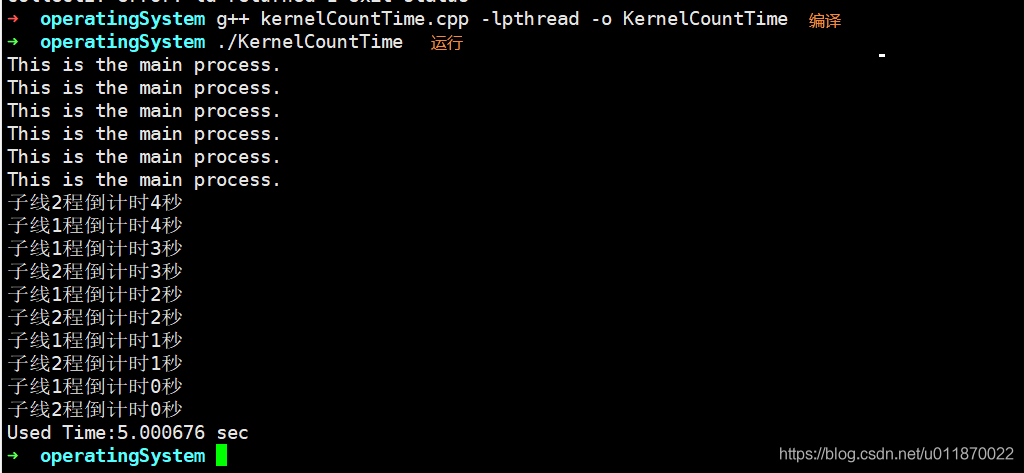
如果手动编译KernelCountTime.cpp文件时,是这样子编译:
g++ KernelCountTime.cpp -o KernelCountTime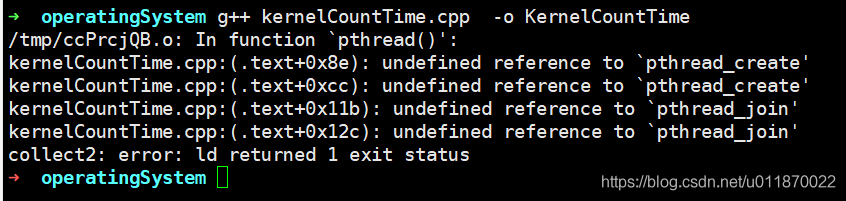
这个会报错,这是因为在Linux中多线程包 pthread依赖库需要在编译的时候在参数列表中显式从依赖库中导入。具体可以参考博客:https://blog.csdn.net/qq_20302045/article/details/106637447
正确的编译命令为:
g++ KernelCountTime.cpp -lpthread -o KernelCountTime6.调试记录
注意,编译KernelCountTime.cpp的是时候必须加上"-lpthread"这个参数,否则会发生编译错误!
g++ KernelCountTime.cpp -lpthread -o KernelCountTime
7.自我评析和总结
在课程设计开始的时候,我对这个实验几乎都不了解,对这个内核的概念也不清楚,所以我首先去查阅资料,把整个概念搞懂.我首先查看了关于Linux内核的概述文献,然后再去了解内核定时器的原理和运行机制,并且在这个过程中参考了大量的博客资料,深入了解了Linux多线程pthread的基本结构和源码,搞懂它们的运行机制,并且在这个过程中,通过学习C++的Signal和多线程程序函数,更加深入了解了Linux的信号机制和多线程运行机制。当然,在这个过程中,由于对系统内核概念的不熟悉以及所学的知识有限,遇到了很多的困难和bug,特别是在测试多线程和那个信号机制时,由于之前没有学过C++的这些编程,导致在进行测试的时候花费了大量的时间。并且在查看c++头文件time.h的过程中,更加了解到了获取系统时间函数,并将之用于我们计算多线程运行时的时间计数器,从而到到我们本次实践的目的。
总的来说,Linux系统内核是一个很高深的东西,以我目前的水平只能学到一点点的皮毛,并将之用于课内实践中。当然,实践的最主要目的是要学到新的知识,并且将学到的知识应用到我们的实践中去,这样相辅相成,才能让我们的知识更加充实。
8.参考文献
[1]《Operating System Concepts(Sixth Edition)(操作系统概念)影印版》 Abraham Silberschatz编 高等教育出版社 2003年
[2]《操作系统原理与设计》
[3]《操作系统原理(第三版)》 庞丽萍 华中科技大学出版社2000年
[4]Linux源码 https://github.com/LJF2402901363/linux.git

