









1.实验教学目的与要求
随着社会经济的迅速发展,越来越多的社会岗位供招聘者选择,如何快速有效的提升自己在意向工作上的技能是我们找到满意工作的第一步。 网络爬出作为一种自动从海量数据中筛选并提出有效信息的工具,可以帮助我们从开放域中汲取所求。本实验通过一个具体的爬虫例子,要求学生自己动手编写代码,挖掘目标信息,并且对信息进行分析利用。通过工程实践加深对理论知识的深入理解和综合应用,进一步提高实际动手能力。
要求学生在上机前应认真做好各种准备工作,包括 python 环境以及相关依赖包的安装及基本操作的熟悉,熟悉爬虫的基本代码编写。
2.实验思路的描述(以猎聘网为例)
2.1步骤
①首先前端页面会发送一个请求,请求参数为:搜索关键字,省文本,市文本。
②使用默认的保存文件的文件夹路径(textFilePathDir)和搜索关键字(searchContent)和市文本对应的编码(dqs)构成一个json格式的文件路径(用于保存jobList对应json格式的字符串)和一个txt格式的文件路径(用于保存所有工作岗位描述的文本内容)。比如文件夹的相对路径为"static/file"搜索文本为 “算法工程师”,地区为北京市,其对应的区域编码为010,则会生成两个文件路径“static/file/算法工程师010.json”和“static/file/算法工程师 010.txt”。
③首先获取txt文件格式的文件对应的字符串,比如"static/file/算法工程师 _ 010.txt"文件的文本内容,如果该文件存在并且获取的文本内容不为空,那么说明本次搜索已经在之前有搜索过然后保存到了本地中,这时候我们只需要从本地中再读取“static/file/算法工程师_010.json”的文件然后转换为jobList集合即可;若是该文件不存在获取获取的文本内容为空,那么说明该搜索是第一次搜索,需要从网络中爬取下来,然后再保存到本地中去。
④若此次搜索已经存在,则直接返回从本地获取的数据,将json文件中的json对象读取为jobList对象,将txt文件读取为jobDesText文本,并且除去一些非必要的词汇标点对文本进行过滤筛选,然后将jobDesText进行分词并统计前十的频率,再生成词云图,最后将分词统计的频率和所有工作信息以json格式的字符串返回到前端页面中用于渲染数据和展示词云图。;若此次搜索是第一次搜索,则需要首先爬取到所有工作的信息和工作的岗位描述,将所有的工作信息以json格式文件保存到本地,将所有岗位要求jobDesText的文本以txt格式保存到本地中去;jobDesText并且除去一些非必要的词汇标点对文本进行过滤筛选然后进行分词统计前十的频率,再生成词云图,最后将分词统计的频率和所有工作信息以json格式的字符串返回到前端页面中用于渲染数据和展示词云图。
2.2流程图
其中requestService.singleThreadHandleSearch(searchContent, province, city)需要处理复杂的业务逻辑,这里采用的是单线程进行处理。
(1)通过配置文件获取对应的province和city对应的城市编码。
(2)从配置文件中加载需要的内容。
(3)根据搜索内容以及城市编码拼接文件路径并判断该文件路径是否存在,如果已经存在本地则直接从本地中获取数据;否则从网络上爬取数据。
(4)如果本地已经存在本次搜索内容,那么从本地中获取本次内容。首先将所有工作的岗位要求文本读取成jobDesText,然后读取所有工作的json对象,并将json对象转换成一个jobList数组。
(5)如果本地不存在,则从网络上爬取数据。
5.1由于猎聘网中每个关键词的搜索结果都有十页数据,所以要逐页数据获取,拼接URL,每次改变URL中curPage的值即可。
5.2发送请求,获取一页数据的源代码,将每个job的具体信息封装到一个Job对象中去,最后将每个Job添加到pageJobList中去。一页数据对应一个pageJobList.共有十页数据,也就是十个pageJobList。
5.3将十个pageJobList的每个job添加到jobList中去。
5.4从jobList中获取每个job的岗位要求拼接到jobDesText,然后以txt格式保存到文件中去。
5.5将jobList转化为json格式的字符串,然后将该字符串以json格式为后缀名保存到文件中去。
(6)jobDesText并且除去一些非必要的词汇标点对文本进行过滤筛选然后进行分词统计前十的频率,再生成词云图,最后将分词统计的频率和所有工作信息以json格式的字符串返回到前端页面中用于渲染数据和展示词云图。
3.解析流程分析
3.1使用BeautifulSoup爬取网页内容
(1)导入BeautifulSoup模块
from bs4 import BeautifulSoup(2)向需要爬取的网站中发送请求,然后获取对应的响应网页HTML源代码并使用BeautifulSoup构建HTML对象。
url = "https://www.liepin.com/zhaopin/?key=Java&dqs=050020&pageSize=80&curPage=1"
# 获取请求URL的对应返回HTML源代码
html_tex = JobUtil.getHtmlTex(url)
# 构建解析对象
soup = BeautifulSoup(html_tex, "html.parser")(3)开始使用selector选择器获取所有工作具体信息的链接
# 获取所有包含职业名称以及职业详细链接的a标签
jobInfoDiv = soup.select(".job-info h3 a") 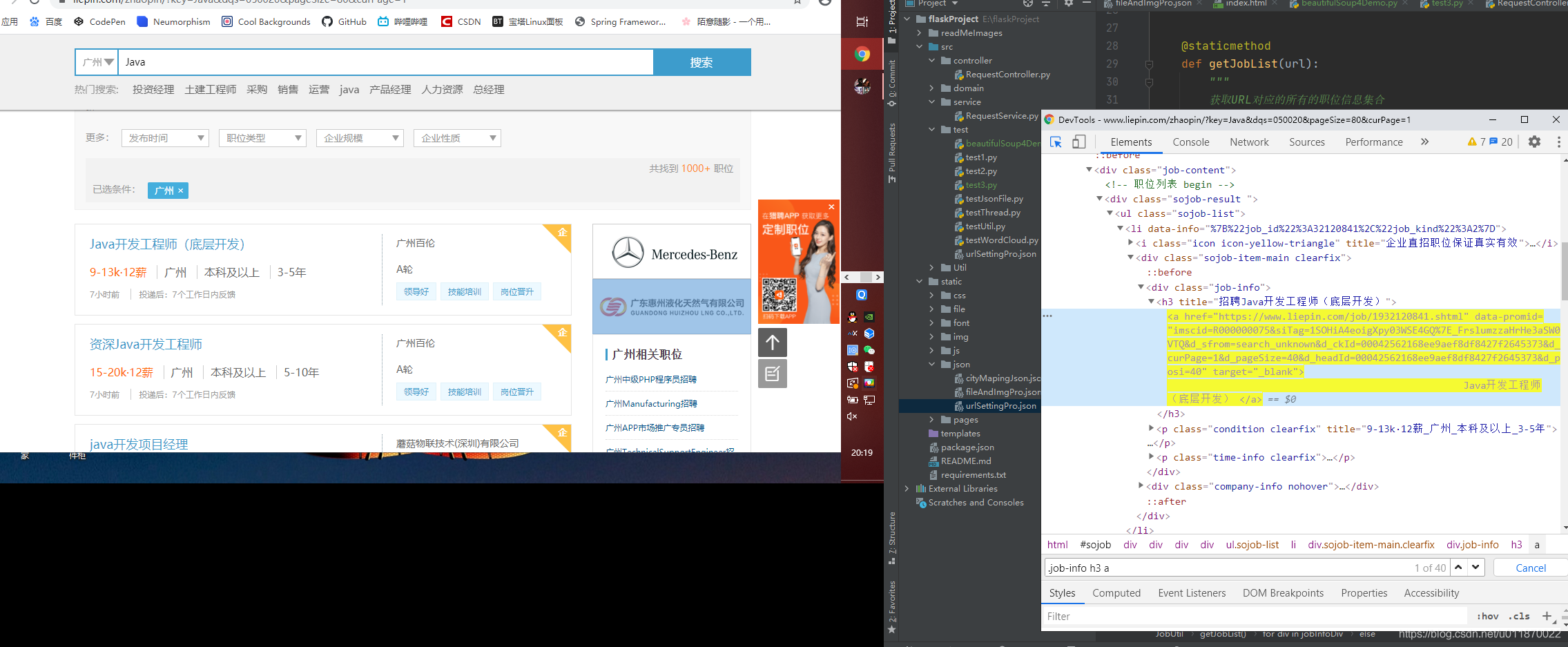
我们发现在这个工作列表中,每一个工作的具体的URL都是在以 class =".job-info h3 a"的选择器对应的a标签中。一般情况下,我们可以通过浏览器的开发工具来进行获取某个标签的选择器。比如要获取这个工作的选择器,我们可以通过F12
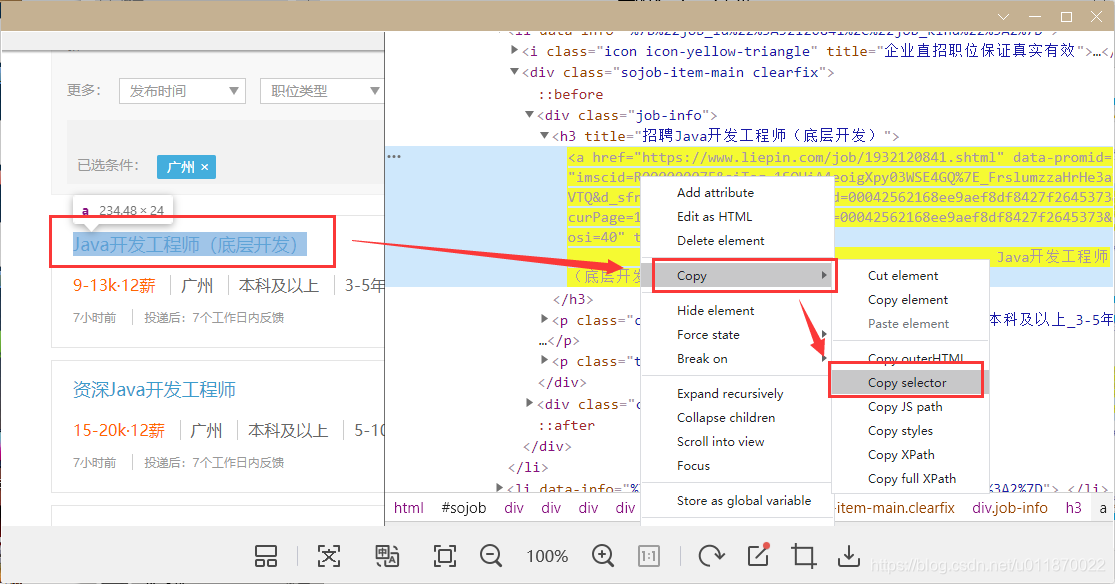
获取到这个工作的具体的URL对应的选择器:“#sojob > div:nth-child(5) > div > div.job-content > div:nth-child(1) > ul > li:nth-child(1) > div > div.job-info > h3 > a”我们发现这个是ID选择器,这个选择器太长了,在一般情况下我们可以截取更短的选择器同样可以达到这个作用。我们可以发现该选择器可以等价于
"div.job-info h3 a"或者".job-info h3 a"这两个都是一样的。我们把这两个选择器放到网页源码中使用搜索功能看看: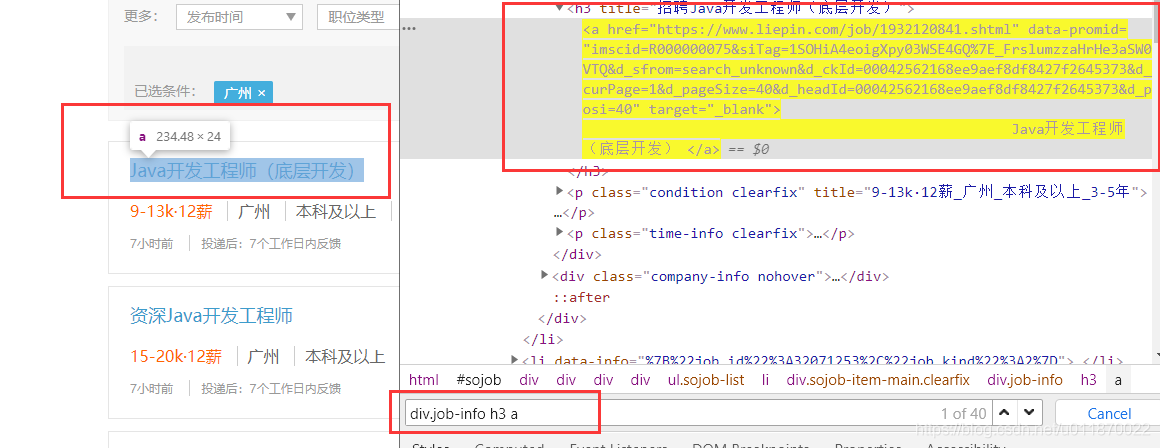
可见我们可以通过更短的选择器来进行获取该工作的URL链接。
(4)获取工作信息的URL后,发送请求获取工作的详细信息的源代码然后通过BeautifulSoup构建解析对象。
①首先将不完整的工作的URL链接补充完成。我们爬取的每个工作的信息的URL有些是采用相对路径来构建链接,比如:“/a/21271755.shtml”这个链接,这时候发现缺少了头部的主网站链接,这样直接发送请求是获取不了对应内容的。我们需要将这个链接补充完整。补偿为"https://www.liepin.com/a/21271755.shtml".可以发现这个要补充的部分就是我们要爬取的完整的URL。
②发送请每个工作具体信息的请求获取对应的源码响应然后使用BeautifulSoup构建解析对象再逐个使用soup.select_one(selector)来获取工作中每一项具体的信息。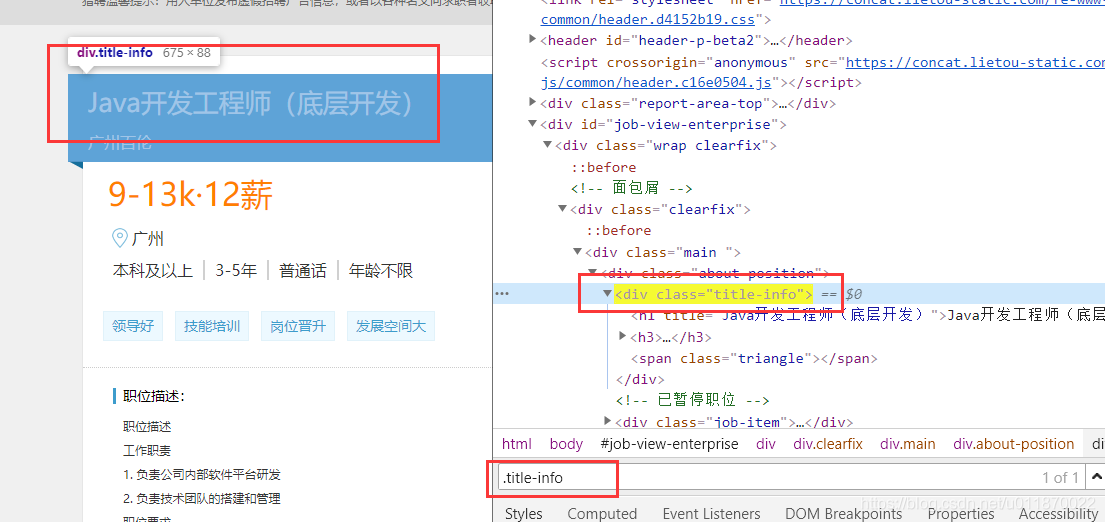
# 获取请求URL的对应返回HTML源代码
html_tex = JobUtil.getHtmlTex(url)
#构建HTML对象
soup = BeautifulSoup(html_tex, "html.parser")
#获取工作名
jobName = soup.select_one(".title-info").text注意:
①.在获取soup.select_one(".title-info")时有可能获取不到对象,或者说获取的是一个None对象,那么这时候soup.select_one(".title-info").text是会报错的。所以在具体获取时我们需要添加判断,其它的具体信息可以相似地获取。
soup = BeautifulSoup(text, "html.parser")
jobNameDiv = soup.select_one(".title-info")
if not jobNameDiv is None:
return jobNameDiv.text
return ""②.在获取soup.select_one(".title-info")时,同样一个职位的各项详细信息在不同的网站中可能源码中选择器selector不一样,比如:工作薪水的选择器就有三个,在不同的网页中选择器是不一样的。这时候我们就要逐个来获取看看是否能获取对象。为了便于获取,我们可以将这些工作信息项具体对应的选择器都配置到一个文件中去,然后需要的时候从配置文件中获取,这样当我们发现有多个选择器的时候,我们可以手动往配置文件中添加而不需要修改代码,这样便给我们提供了很多方便。
".job-item-title",".job-main-title", ".job-title-left"在这里使用的是json格式的配置文件:
{
"jobInfoLinkDiv": {"name1":".job-info h3 a"},
"jobNameDiv": {"name1": "div.title-info > h1"},
"jobCompanyNameDiv": {"name1": "div.title-info > h3 a"},
"jobSalaryDiv": {
"name1": ".job-item-title",
"name2": ".job-main-title",
"name3": ".job-title-left"
},
"jobCityDiv": {
"name1":"div.job-title-left > p.basic-infor > span > a"
},
"jobEduDiv": {
"name1":"div.job-title-left > div > span:nth-of-type(1)"
},
"jobExperienceTimeDiv": {
"name1":"div.job-title-left > div > span:nth-of-type(2)"
},
"jobCodeNameDiv": {
"name1":"div.job-title-left > div > span:nth-of-type(3)"
},
"jobAgeDiv": {
"name1":"div.job-title-left > div > span:nth-of-type(4)"
},
"jobDesDiv": {
"name1":"div.job-item.main-message.job-description > div",
"name2": "div.job-main.job-description.main-message > div"
}
}③.假若工作具体信息的某一项的标签是使用浏览器的开发工具中的获取的,那么若出现nth-child()的,我们需要改为nth-of-type(),比如:
在浏览器开发者工具中使用copy selector复制然后化简的选择器 "div.job-title-left > div > span:nth-child(4)"需要改为"div.job-title-left > div > span:nth-of-type(4)".否则在程序运行时会发生错误。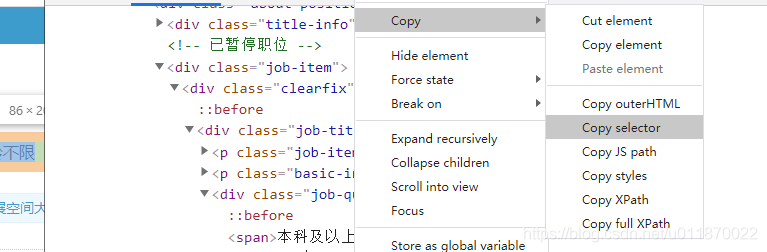
(5)发送请求爬取不到内容很可能是被网站的反爬虫机制给禁止了。这时候我们需要通过一定的方式进行反反爬虫机制。此次使用的是采用随机的User-Agent请求头headers进行发送请求,更高级的可以使用代理ip进行反反爬虫。
①首先安装stall fake_useragent模块。
pip install fake_useragent`在这里插入代码片`②然后引入UserAgent模块:
from fake_useragent import UserAgent③具体使用:
@staticmethod
def getHtmlTex(url):
"""
获取url对应的网页内容,即获取网页的源码便于分析
:param url:
:return:
"""
# 生成随机请求头
header = {"User-Agent": UserAgent().random}
# 获取请求内容
response = requests.get(url=url, headers=header)
# 判定是否成功获取
if response.status_code != 200:
raise Exception("请检查您的URL" + url)
return response.text3.2将每个job的信息封装到job对象后将每个工作加入到jobList集合中去,将所有的job的岗位描述和要求拼接成一个字符串jobDesText。
@staticmethod
def getJobListDesStr(jobList):
"""
获取jobList中岗位要求的全部字符串
:param jobList: 包含岗位集合的list
:return:
"""
jobListDesStr = ''
for job in jobList:
jobListDesStr = jobListDesStr + job.jobDes
return jobListDesStr3.3 将jobList转换为Json对象的字符串格式
@staticmethod
def listToJson(jobList):
"""
将一个list转为json格式
:param jobList:工作集合
:return:返回工作信息的json格式字符串
"""
size = len(jobList)
jobListStr = '['
for index in range(size):
job = jobList[index]
jobListStr = jobListStr + '{"name":"' + job.jobName + '",'
jobListStr = jobListStr + '"city":"' + job.jobCity + '",'
jobListStr = jobListStr + '"edu":"' + job.jobEdu + '",'
jobListStr = jobListStr + '"salary":"' + str(job.jobSalary) + '",'
jobListStr = jobListStr + '"experienceTime":"' + job.jobExperienceTime + '",'
jobListStr = jobListStr + '"age":"' + job.age + '",'
jobListStr = jobListStr + '"jobUrl":"' + job.jobUrl + '",'
if index == size - 1:
jobListStr = jobListStr + '"codeName":"' + job.codeName + '"}'
else:
jobListStr = jobListStr + '"codeName":"' + job.codeName + '"},'
jobListStr = jobListStr + ']'
return jobListStr3.4将Json格式字符串和jobDesText保存到指定的文件中
@staticmethod
def saveTextToFile(text, filePath):
"""
将文本内容text保存到filePath路径中去
:param text: 要保存的文本
:param filePath: 保存到的路径
:return:
"""
# 打开文件
file = open(filePath, mode="tw", encoding="utf8")
# 将文本写入文件中去
file.write(text)
# 刷新缓冲区
file.flush()
# 关闭文件资源
file.close()3.5将jobDesText中无用的标点符号以及一些无关的词给过滤替换为空字符串,然后使用jieba库将jobDesText分词然后统计每个词汇的出现频率。
@staticmethod
def getWordCouldJson(text,wordJson):
"""
将给定的文本进心分词处理,并且添加json格式的新词,在分词过程中wordJSon中的词语不被切分,返回一个json数组
[
{
"name": name,
"value":value
},
{
"name": name,
"value":value
}
]
:param text:需要进行分词的文本
:param wordJson:在分词过程中不被切分的词语的json数组
:return:返回分词一个分词和对应出现频率的json对象数组
"""
for word in wordJson:
jieba.add_word(word['word'],word['freq'])
words = jieba.cut(text) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数
# 统计词频
for word in words:
if len(word) == 1: # 单个词语不计算在内
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1
# 注解:dict.get(word,0)当能查询到相匹配的字典时,就会显示相应key对应的value,如果不能的话,就会显示后面的这个参数
# 有些不重要的词语但出现次数较多,可以通过构建排除词库excludes来删除
items = list(counts.items())
# 根据词语出现的次数进行从大到小排序
items.sort(key=lambda x: x[1], reverse=True)
dictList = {}
for item in items:
dictList[item[0]] = item[1]
# 将字典转换为json对象
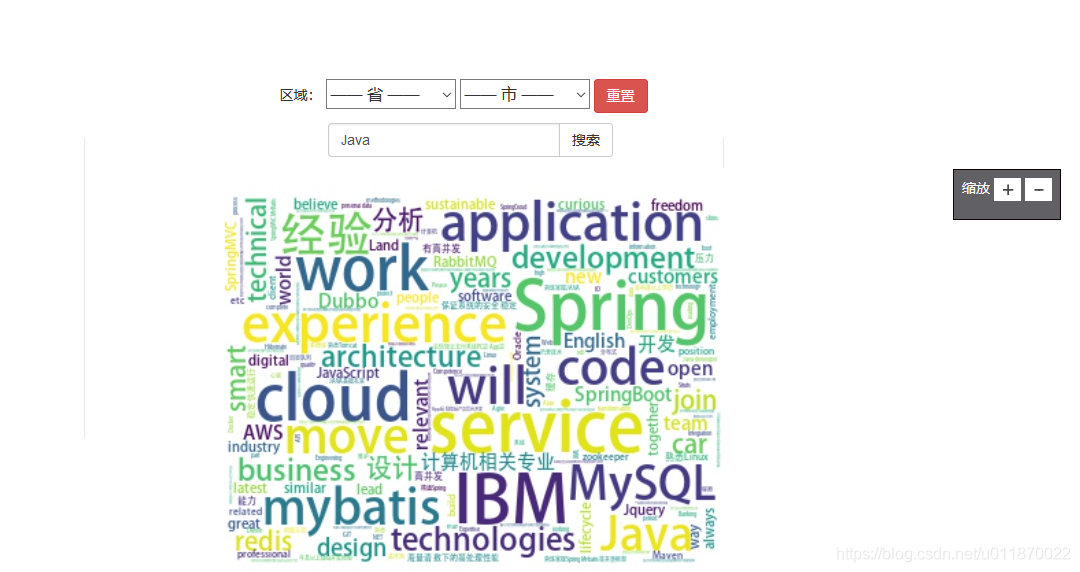
return json.dumps(dictList,ensure_ascii=False)3.6使用wordcloud将岗位描述文本产生词云图。
@staticmethod
def wordCould(text, backGroudImgPath, desPath, scale):
"""
对给定的text文本以backGroudImgPath的图片为背景图片并按照指定的缩放比例scale生成词云,然后写入到desPath路径中去
:param text: 给定的文本
:param backGroudImgPath:背景图片路径
:param desPath: 词云图片存储的目的地
:param scale: 图片的缩放比
:return: null
"""
# 加载背景图
color_mask = np.array(Image.open(backGroudImgPath))
wc1 = WordCloud(
scale=scale, # 图片的缩放比例
mask=color_mask, # 背景图颜色
background_color='white', # 背景颜色
height=300, # 图片高度
width=500, # 图片宽度
max_font_size=100, # 字体最大值
random_state=100, # 配色方案的种类
font_path="static/font/AdobeHeitiStd-Regular.otf", # 不加这一句显示口字形乱码
)
# 产生词云
wc1.generate(text)
# 在只设置mask的情况下 会得到一个拥有图片形状的词云 axis默认为on 会开启边框
plt.imshow(wc1, interpolation="bilinear")
plt.axis("off")
# 将图片保存到指定的目录文件中去
plt.savefig(desPath)3.7将获取的词频以及jobList信息格式化为json数据格式然后返回给前端页面。
@staticmethod
def jsonListToViewJson(jsonObj, jobList,wordCouldImgPath,status,msg):
"""
将一个json对象转换为符合前端页面展示数据的json字符串
格式:
{
"data":
{
"words":
[
{ name: key}
],
"jobInfoData":[{
name:key
}]
},
"wordCouldImg":"词云图保存路径",
"status":1,
"msg":"提示的内容"
}
"status":1}
:param jobList: 所有职位的列表
:param jsonObj: 需要转换的json对象数组
:param wordCouldImgPath: 词云图的图片路径
:param status: 状态
:param msg: 返回前端页面的提示信息
:return: 返回一个json格式字符串
"""
jsonstr = '{ "data":{ "words":['
index = 0
count = 0
for obj in jsonObj:
index = index + 1
if index <= 10:
jsonstr = jsonstr + '{"name":"' + obj + '","value":' + str(jsonObj[obj]) + "},"
else:
count = count + jsonObj[obj]
jsonstr = jsonstr + '{"name":"其它","value":' + str(4) + "}],"
jobListStr = '"jobList":['
size = len(jobList)
for index in range(size):
job = jobList[index]
jobListStr = jobListStr + '{"name":"' + job.jobName + '",'
jobListStr = jobListStr + '"city":"' + job.jobCity + '",'
jobListStr = jobListStr + '"edu":"' + job.jobEdu + '",'
jobListStr = jobListStr + '"salary":"' + str(job.jobSalary) + '",'
jobListStr = jobListStr + '"experienceTime":"' + job.jobExperienceTime + '",'
jobListStr = jobListStr + '"jobUrl":"' + job.jobUrl + '",'
jobListStr = jobListStr + '"age":"' + job.age + '",'
if index == size - 1:
jobListStr = jobListStr + '"codeName":"' + job.codeName + '"}'
else:
jobListStr = jobListStr + '"codeName":"' + job.codeName + '"},'
jsonstr = jsonstr + jobListStr + ']'
jsonstr = jsonstr + ',"wordCouldImg":"' + wordCouldImgPath + '"}'
jsonstr = jsonstr + ',"status":' + str(status) + ',"msg":"' + msg + '"}'
# print(jsonstr)
return jsonstr3.8文件命名
①单线程时生成的文件命名为:
保存工作对象信息的json文件为名为: “搜索文本区域编码.json",岗位要求信息的txt文件名为:“搜索文本 区域编码 .txt”。比如搜索文本为 “算法工程师”,地区为北京市,其对应的区域编码为010,则会生成两个文件“算法工程师010.json”和“算法工程师 010.txt”.其它依次类似。
②多线程时生成的文件命名为: 使用多线程爬取数据时是分为十页,每一页数据都用一个线程来爬取。每一页的数据中工作信息对象集合保存到一个json文件中去,其格式为 “搜索文本区域编码 页码.json",工作的要求和描述保存到一个txt文件中去,其格式为“搜索文本 _ 区域编码 _ 页码.txt".比如搜索文本为 “算法工程师”,地区为北京市,其对应的区域编码为010,则会生成十个json文件,十个txt文件。
“算法工程师 _ 010 0.json”和“算法工程师 010 _ 0.txt”;
“算法工程师 _ 010 1.json”和“算法工程师 010 _ 1.txt”;
“算法工程师 _ 010 2.json”和“算法工程师 010 _ 2.txt”;
……..
“算法工程师 _ 010 9.json”和“算法工程师 010 _ 9.txt”;
4效果图
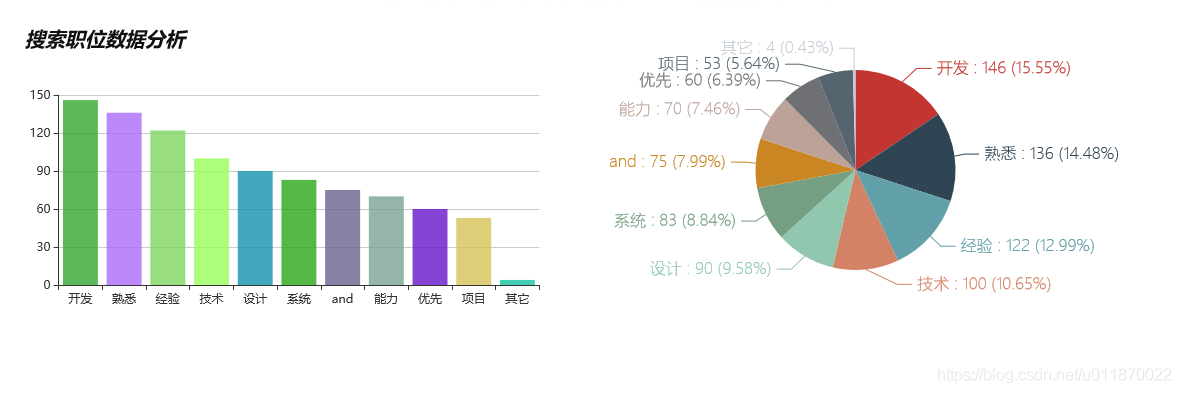
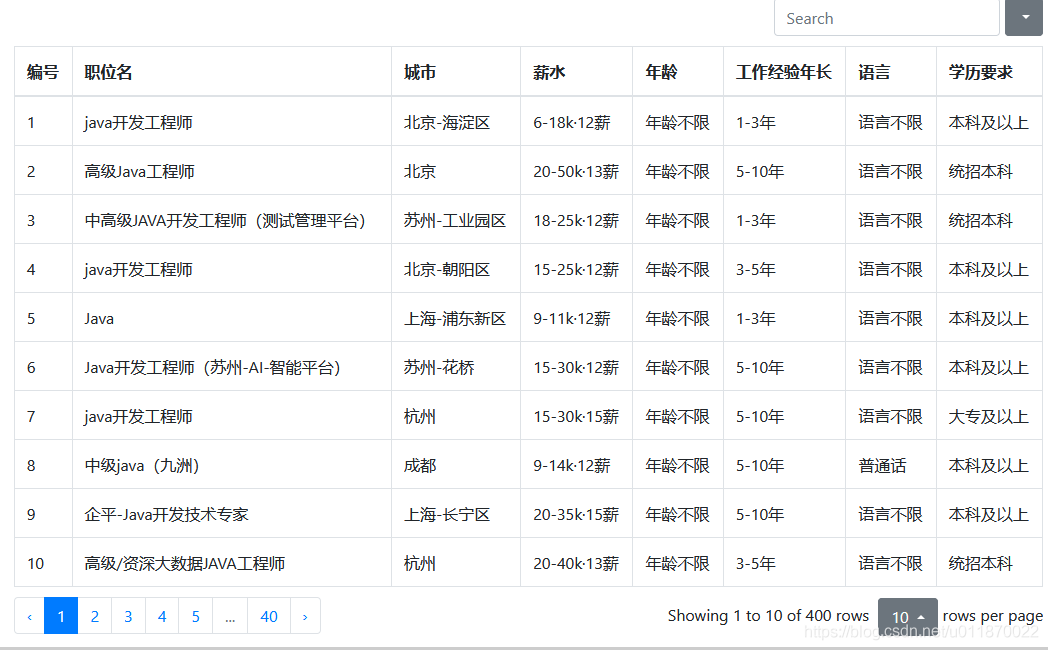
5.项目地址
GitHub地址:求职APP的GitHub项目地址
Gitee地址:求职APP的gitee地址
6.项目启动
6.1首先使用Git命令将项目从GitHub或者gitee(速度更快,并且还能看到文档中的图片便于照着运行程序,建议使用gitee)上拉取到本地
git clone https://github.com/LJF2402901363/JobSearchApp.gitgit clone https://gitee.com/ljf2402901363/JobSearchApp.git6.2使用pycharm打开项目
使用pycharm的控制台Terminal使用命令安装依赖包:
pip install -r requirements.txt
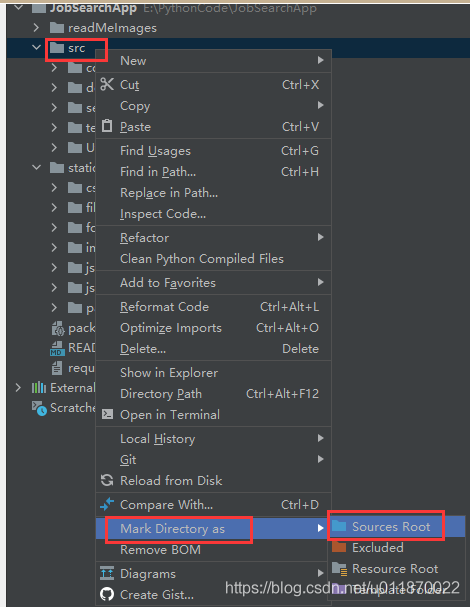
6.3使用右键将src目录,找到Mark Directory as ,将src目录设置为 Sources Root
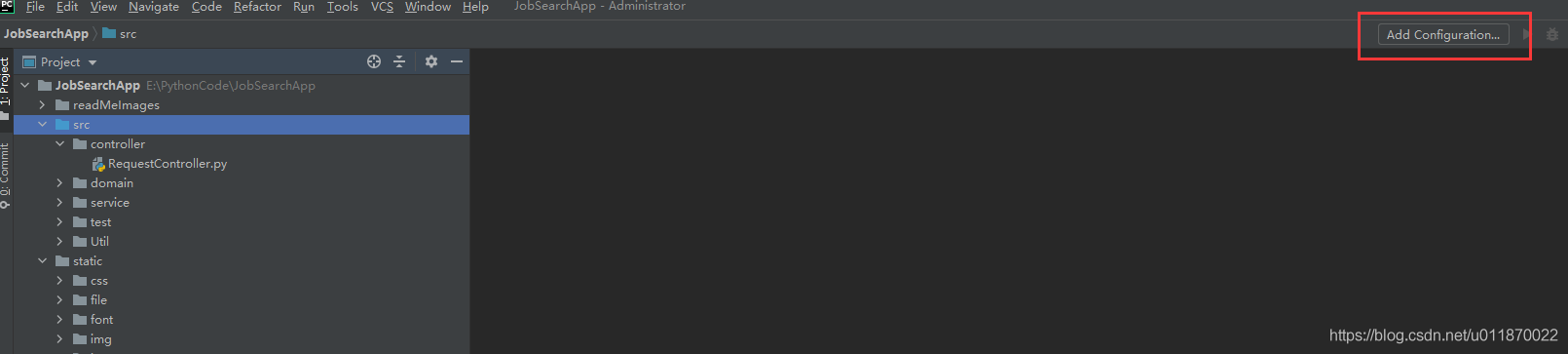
6.4配置Flask
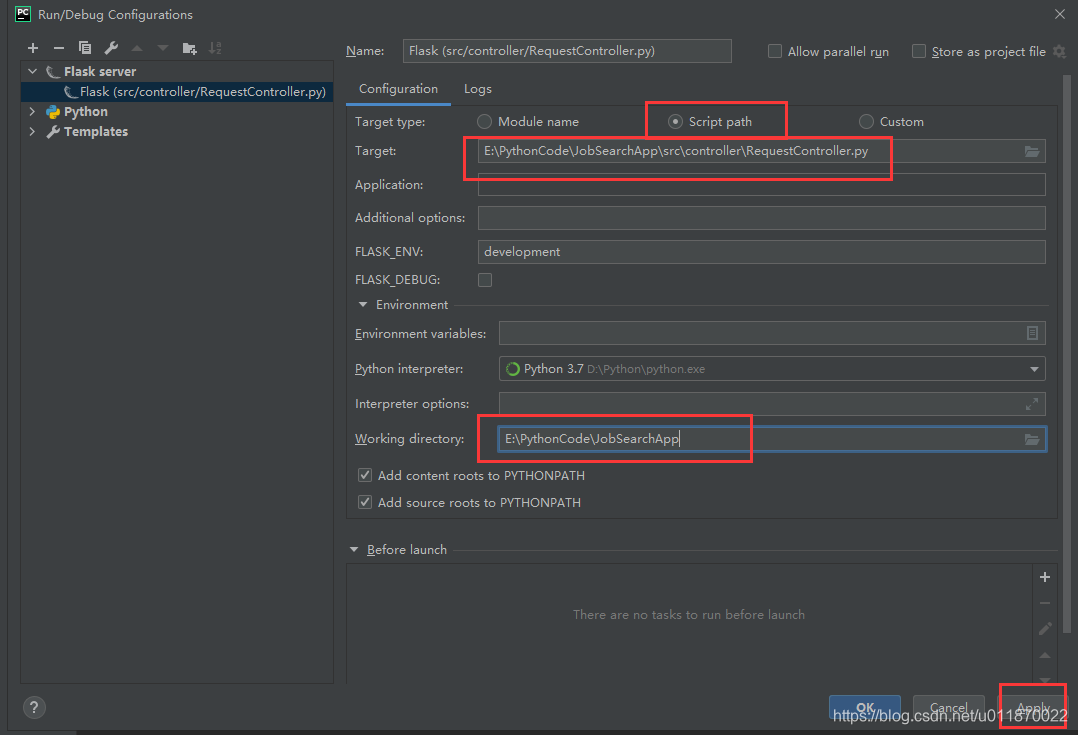

Target:指定Flask项目中run方法所在的.py文件。本项目中位于controller包下的RequestController.py下。
Working directory:指定工作目录。这里指定项目根目录即可。
6.5目前笔者仅在pycharm上运行本项目。要是使用该其它编译器运行比如vscode,会导致目录路径结构不一样从而加载配置文件时出现错误。而加载配置文件核心所在类即是Util包下的JsonUtil.py
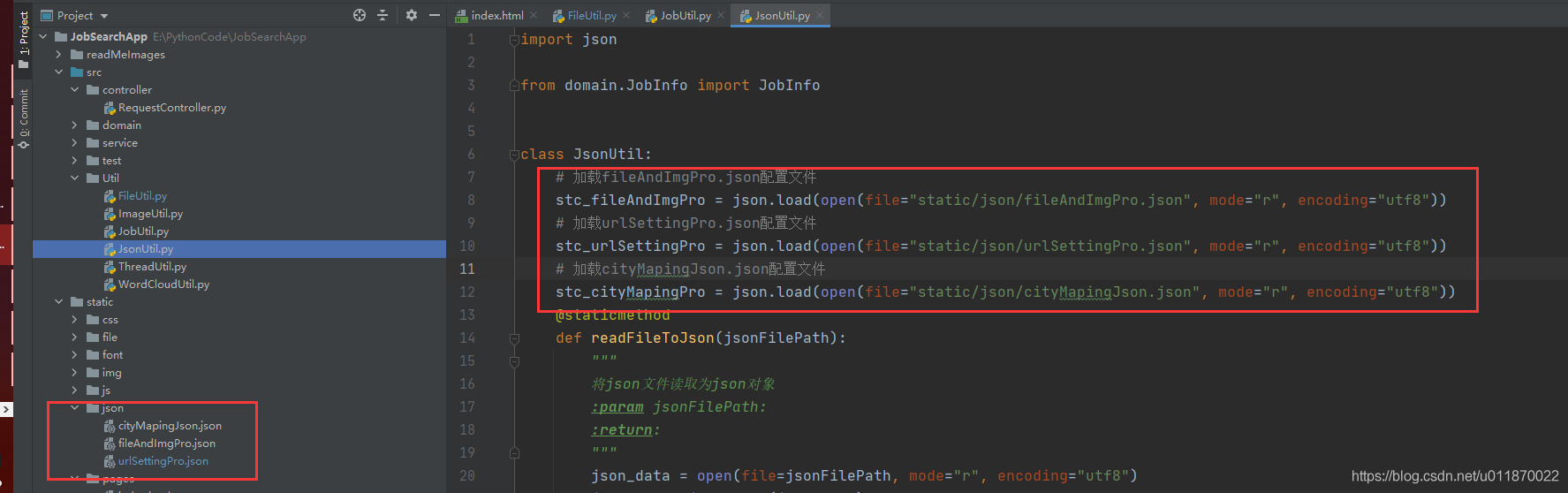
只需要加载的路径和对应json文件所在的路径一致即可。至于其他问题请自行解决,只要不报能够解决引入自定义包文件即可。
7.本项目已经打包上传到个人服务器,点击即可下载(下载后运行和GitHub或者gitee拉取下来后运行一致):http://moyisuiying.com/wp-content/uploads/2020/10/JobSearchApp.rar

